Recoding Data
Creating New Columns
As questions arise during your data exploration and cleaning, you might want to investigate. In this instance, we want to make sure the values we are planning on manipulating remain untouched. One thing we can do is add a new column that will contain our manipulations.
Example
import pandas as pd
data["survived_reformatted"] = data["survived"].replace({0 : False, 1: True})The above code accomplishes the following:
- Imports pandas
- Creates a new column called
survived_reformattedfrom thesurvivedcolumn after replacing all0and1integers with eitherFalse, orTrue.
Viewing the output of the dataframe you are able to see that a new column called survived_reformatted was created:

Replacing Values
Replacing values within a column to be more data friendly is a common practice. In particular, replacing strings of data to bools, where a “yes” or “no” would become True or False. We can accomplish this by using the .replace function.
The following example simply replaces the data that exists within the column, manipulating it directly as it is, without creating a new column from the manipulation itself.
Example
Replace the “0” and “1” integer values within the survived column of the Titanic dataset to True or False by passing in a dictionary as an argument into the to_replace.
import pandas as pd
data["survived"] = data["survived"].replace(to_replace={0: False, 1: True})Using Functions to Manipulate Data
Creating a function to aggregate data or create new columns is another common practice used when analyzing data. Pandas utilizes the .apply() method to execute a function on a pandas Series or DataFrame.
Example
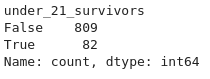
Suppose you wanted to know how many survivors age 20 and under are still alive from the titanic dataset:
import pandas as pd
data = pd.read_csv("titanic.csv")
def age_20_and_under_survivors(data):
age = data['age']
alive = data['alive']
if age <= 20 and alive == "yes":
return True
else:
return False
data["age_20_and_under_survivors"] = data.apply(age_20_and_under_survivors, axis=1)
print(data["age_20_and_under_survivors"].value_counts())Output
Summary
When recoding your data there are some things you should think about:
- Does the original data need to remain intact?
- What data types should be replaced with new values, and what type of data should the new value be?
- Would a function be useful for repetitive tasks and manipulation?