Aggregation
Note
This reading, and following readings, will provide examples from the titanic.csv dataset file that will also be used in the exercise portion of this chapter.
Groupby
The .groupby() function groups data together from one or more columns. As we group the data together, it forms a new GroupBy object. The official pandas documentation
states that a “group by” accomplishes the following:
- Splitting: Split the data based on the criteria provided.
- Applying: Provide an applicable function to the groups that were split.
- Combining: Combine the results from the function into a new data structure.
Syntax
Syntax for the .groupby() method when providing a single column as a parameter is as follows:
grouping_variable = your_data.groupby("column-name")Example
Let’s take things a step further and aggregate the data within the grouped column name using the .sum() function through method chaining:
grouping_variable = your_data.groupby(["column_name"]).sum()The above code will group the dataset by ‘column_name’, and will then return the sum of all values within each column grouped by each unique value in the ‘column_name’ column
The .groupby() method can take multiple columns as a parameter upon creation, but it is best practice to only provide as many columns as needed for your analysis. As you increase the amount of grouped columns, you are also increasing the amount of compute power and memory needed, which can lead to performance issues.
In order to group multiple columns you can pass a list of column names as a parameter to the .groupby method.
grouping_variable = your_data.groupby(["column_one", "column_two", "etc.."])Example
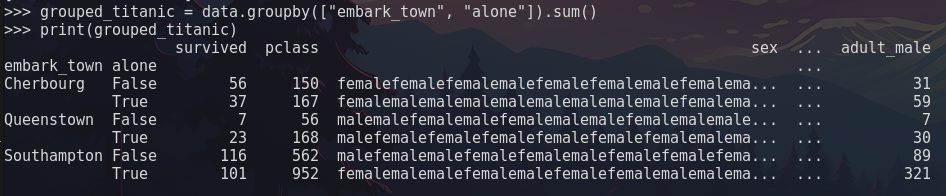
Applying an aggregate function to multiple grouped columns can also be accomplished with method chaining. The following image uses columns from the titanic dataset as an example.
The image below displays the output when only applying the groupby() method to only the embark_town column.

The key thing to note here is that when grouping multiple column(s) together it will provide you a dataset that is specific to that grouping of data. When theembark_town column was grouped with the alone column, the result is a dataset that provides an aggregate of the entire dataset in relation to those two columns. When embark_town was grouped alone, it provided an aggregate of the entire dataset only as it relates to the embark_town column.
Aggregate Methods
pandas provides a built-in aggregate method: Data.aggregate() or Data.agg() (both accomplish the same thing, agg() is short for aggregate()). The benefit of using the .aggregate() function is that it allows you to pass aggregate functions as a list.
Example
data.agg(['mean', 'median', 'mode'])Warning
Note that the mode() function can return multiple values per column if there are multiple modes (values that appear with equal frequency). This may result in a DataFrame with more rows than expected. If you need only one mode value, you may want to use mode()[0] or apply mode to specific columns individually.
Aggregation Using a Dictionary
pandas also allows the ability to provide a dictionary with columns as a key and aggregate functions as an associated value.
Example
| |
This dictionary object has now become a template for the aggregations we want to perform. However, on it’s own, it does nothing. Once passed to the agg() method, it will pick out the specific location of data we want to examine. Making a subset table.
Groupby and Multiple Aggregations
A common strategy used when applying multiple aggregations to your group or dataset is to hold them within a variable. The advantage of this being, you will not have to provide the list of functions you need as parameters each and every time.
Example
| |