SQL Subqueries
Subqueries are similar to nested IF statements in that it is a SQL statement nested inside of another. Like conditionals, one of the main use cases for subqueries is to apply additional logic or filtering to your data. As that is the case, subqueries are most often nested inside of a WHERE or HAVING clause although, it is not required.
The structure of a subquery has the following attributes:
SELECTqueryFROMclause- optional
WHEREclause - optional
GROUP BYclause - optional
HAVINGclause
- optional
- Must be wrapped in parentheses
One of the many benefits of using subqueries is that it allows you to apply aggregate functions within WHERE clause that you will see in an example below.
Note
The following examples will reference the tables Movies and More_Movies. You can view tables data here: Movies and More_Movies table data
Non-Correlated Subqueries
Non-correlated subqueries are queries that can run on their own regardless of the outer query. This type of subquery will only run one time instead of executing row by row.
Example
The example below will utilize a nested subquery to return the row with the max Rotten Tomatoes score:
| |
Output

The output of a simple one-line SELECT query when applying an aggregate function would look like the following:
SELECT MAX(rt_score) FROM Movies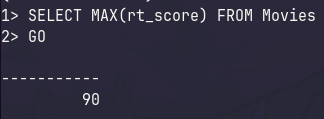
One major difference to note here is that when the aggregate function is applied using a subquery you receive the entire row of data as a result, instead of just the single value that satisfies the aggregate function within the column.
Example
What if you wanted to produce a result set of movies from the More_Movies table with a higher score than the average score of all movies within the Movies table? Let’s start by gathering the average score from the Movies table:
-- gather average score from Movies table
SELECT AVG(rt_score) FROM Movies
GOResult
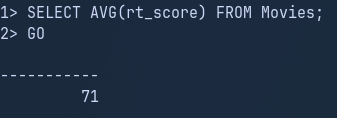
Now let’s apply the same logic within a subquery:
-- Select all data from More_Movies
SELECT * FROM More_Movies
-- Apply condition that we only want movies with a rt_score greater than --> subquery statement/expression
WHERE rt_score >
-- Use subquery to gather AVG rt_score from the Movies table (this is non-correlated as it does not reference and columns within the More_Movies table)
(SELECT AVG(rt_score) FROM Movies)
GOResult
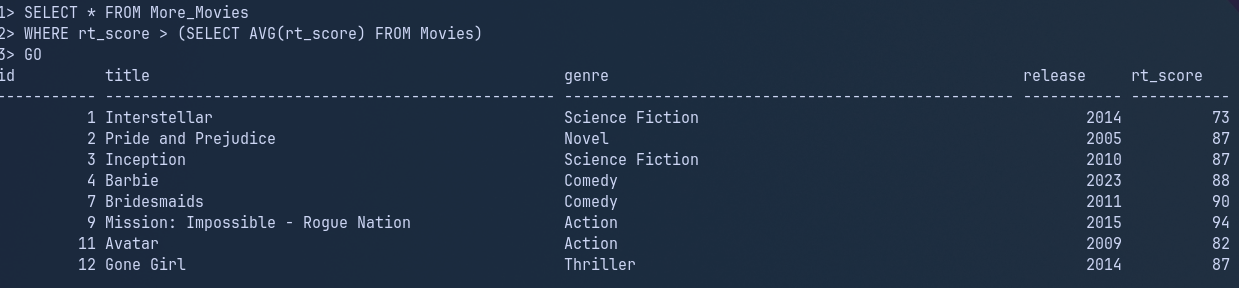
Example
The last non-correlated example will utilize the IN keyword within a WHERE clause.
-- Select all from Movies
SELECT * FROM Movies
-- Filter outer query based on genres from inner query
WHERE genre IN (SELECT genre FROM Movies WHERE rt_score > 88);
-- Will result in all movies that are within genres that have a minimum of one film with a score above 88
GO
The same query and subquery using the More_Movies table:
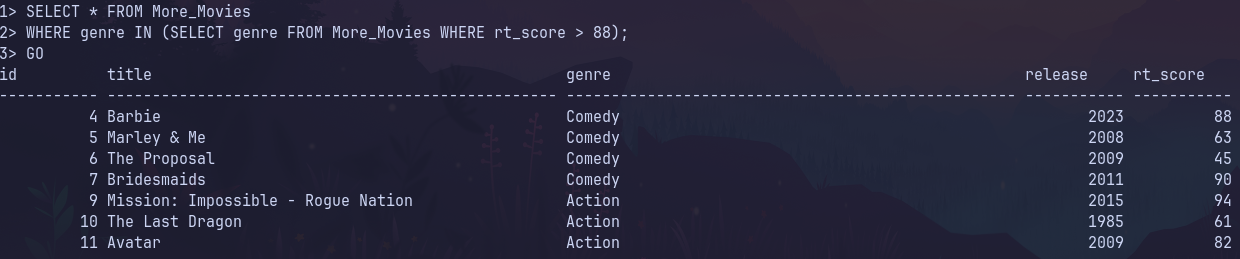
Correlated Subqueries
Correlated Subqueries are inner queries that rely on data from a column specified in the outer query. A common trait among correlated subqueries is that they will execute once for every row in the outer query and cannot execute on its own. This process can be rather performance intensive and consume lots of memory if you are working on larger datasets.
Let’s take a look at an example below:
Example
-- Select all from the Movies table and create an alias (m1) for it
SELECT * FROM Movies AS m1
-- Where clause
WHERE rt_score = (
-- subquery to select max rt_score from movies and create a new alias (m2) for it
SELECT MAX(rt_score) FROM Movies AS m2
-- subquery where clause to compare movies within the same genre
WHERE m1.genre = m2.genre
-- check rt_score against movie with highest score
AND m1.rt_score <= m2.rt_score
)
GOResult

---
title: Non-Correlated and Correlated Subqueries
---
graph LR;
A[Non-Correlated] --> B(self-contained) --> C(executes only once)
D[Correlated] --> E(cannot execute alone) --> F(executes per row)
Check Your Understanding
Question
Is the following block of code an example of a correlated or non-correlated subquery?
SELECT * FROM More_Movies
WHERE release IN (
SELECT release from More_Movies
WHERE release > 2010
)
GO