Sed From STDIN
sed from STDIN
So far you have only performed sed substitute commands using a file as input, however you can re-route STDOUT from another command to use as the STDIN for sed.
This allows you to combine sed with other tools like grep.
In this example you will be using grep to match users with a specific last name. However, you don’t want the Company the person works for, just their first and last names, and their email address. So you will use sed to trim out the company of our filtered dataset.
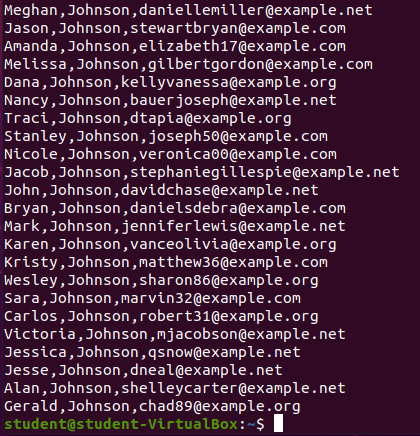
grep Last Name: Johnson
grep '^[^,]\+,Johnson' user-data.csvOutput:
![grep ‘^[^,]+,Johnson’ user-data.corrected.csv output](https://education.launchcode.org/linux/userspace-applications/walkthrough/sed/sed-from-stdin/pictures/grep-johnson.png?classes=border)
This grep and regular expression combo matched all individuals with a first name, and the last name of Johnson.
Note
This grep command is using two regular expression symbols you have not seen before:
[^,]: exclusion group, match any character other than the characters found inside of the match group[^]in this case a comma,+: match at least one, but as many additional characters that fit the pattern
Altogether: '^[^,]\+,Johnson' is a regular expression for:
- match the beginning of the line (
^) - match any character except for characters found in the exclusion group, in this case just a comma (
,) - match at least one of the preceding pattern (anything but comma), but as many characters as you can:
\+ - match exactly one comma (
,) - match exactly
Johnson
Sally,Johnson: matchFred,Johnson: matchSally,Kemper: no match,Johnson: no matchFred,,Johnson: no match
sed Substitute Company with Nothing
As of now the output contains all the people you want to email, but you currently have each person’s employer, which you don’t care about. Let’s substitute and replace the company with no characters, effectively deleting the section.
grep '^[^,]\+,Johnson' user-data.corrected.csv | sed 's/[^,]\+//4'Output:
![grep ‘^[^,]+,Johnson’ user-data.corrected.csv | sed ’s/[^,]+//4’ Output](https://education.launchcode.org/linux/userspace-applications/walkthrough/sed/sed-from-stdin/pictures/grep-sed-remove-company.png?classes=border)
That was pretty slick. Let’s break down the sed substitution: s/[^,]\+//4.
s/regex/replacement-text/flags: substitute/[^,]\+/: regex saying match at least one charcter not in the exclusion group (comma), but match as many as possible//: empty replacement-text, after matching the pattern it should substituted with nothing/4: make the substitution on the 4th match in the line
Note
You can visualize the four sections with grep and it will give you a better understanding of exactly what was replaced with nothing on each line:
grep '^[^,]\+,Johnson' user-data.corrected.csv | grep '[^,]\+'Output:
![grep ‘^[^,]+,Johnson’ user-data.corrected.csv | grep ‘[^,]+’ output](https://education.launchcode.org/linux/userspace-applications/walkthrough/sed/sed-from-stdin/pictures/grep-grep.png?classes=border)
Take note that each line has matched exactly four segments, but no actual commas.
- the first name would be removed by providing a
1flag - the last name would be removed by providing a
2flag - the email would be removed by providing a
3flag - the company would be removed by providing the
4flag - all matches would be removed by providing the
gflag (which would only leave the three commas).
sed Substitute Hanging Command with Nothing
At this point in time we have our email list: all the Johnsons, their emails, but not their employer.
Each line has a hanging comma. The hanging comma can be matched and substituted with sed:
grep '^[^,]\+,Johnson' user-data.corrected.csv | sed 's/[^,]\+//4' | sed 's/,//3'Output:
![grep ‘^[^,]+,Johnson’ user-data.corrected.csv | sed ’s/[^,]+//4’ | sed ’s/,//3’ output](https://education.launchcode.org/linux/userspace-applications/walkthrough/sed/sed-from-stdin/pictures/grep-sed-sed.png?classes=border)
Goodbye trailing comma!
Writing the Stream
The matched lines (grep) and substitutions (sed) have transformed our user-data.corrected.csv in to a family email list for the Johnsons, but the end result has been displayed to STDOUT.
STDOUT can be redirected to a file by using the bash redirection operator (>) that results in a file with the matching, and substitutions:
grep '^[^,]\+,Johnson' user-data.corrected.csv | sed 's/[^,]\+//4' | sed 's/,//3' > johnson-email-list.csvValidation
Check the contents of the working directory:
lsOutput:
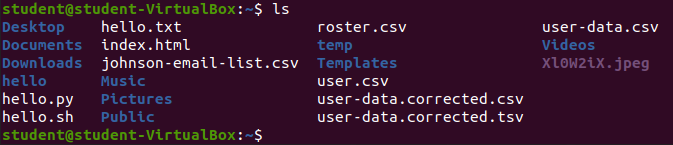
Check the contents of the file:
cat johnson-email-list.csv