In this article, we’ll walk through deploying a Spring Boot application to Pivotal Web Services using Cloud Foundry. Along the way, we’ll address other topics to consider when deploying an application, such as database hosting and migration, password management, and network routing.
Contents
This article assumes you have the following installed:
Pivotal Web Services will be the cloud hosting provider for this article. There are many cloud hosts available to consider (Amazon, Azure, etc), but we’ll be using Pivotal because it has a lot of support for deploying Spring Boot applications and is relatively inexpensive.
Create a Pivotal Account. You will need to provide a credit card number and a phone number to verify your account. Later in this guide, we’ll cover how to make sure everything is un-deployed so you don’t incur any nasty hosting fees.
Once an account has been created, you will want to create a space. Developers typically use spaces to create segments to their environments, and may have one for production, development, testing, and so on. You should have an empty dashboard with a card present to ‘+ Add a Space’. Do so, and create a space named “Production”.
We’ll be using a tool called Cloud Foundry to manage our deployment. Cloud Foundry is widely used in the industry to manage applications and services. It provides tools to package and deploy our code to production with minimal configuration.
If you haven’t already, install the Cloud Foundry CLI. This tool will connect our computer to our Pivotal account, and allow us to deploy and manage our apps.
In a terminal, log into your Pivotal account:
$ cf login
You should see your email, organization name, and the space you just created on the confirmation message.
This article will be based off of the coding-events project used in the LC101 Java curriculum.
Note
While we have to choose a specific project for the purposes of illustration, any Spring Boot project could be deployed using the same steps used in this guide.
Clone this project and checkout the auth-filter branch. Base a new branch
off of this called deploy. If you’d like to keep the
changes we’ll be making in your GitHub account, first fork the project to your own repository,
and continue based on the new Git repository url.
Here are the Git commands to carry out these steps.
$ git clone https://github.com/LaunchCodeEducation/coding-events.git
$ git checkout --track origin/auth-filter
$ git checkout -b deploy
Tip
It’s a best practice to create a Git branch solely for the purpose of deploying your application. We’ll use the deploy branch for this purpose. This will allow for separate configurations to be stored for local development and remote deployment.
If you don’t have a database user for this project already—you may have
created one when going through unit 2—you should create one now. Create
a new database user called coding-events (along with the corresponding
database.) You should now be able to start the application using
gradle bootRun at the command line, from the project root.
Typically, when we’re working on our projects, we’re building and running them locally. We have tools like Gradle and our IntelliJ that help us. These tools make compiling and running our application simple. We won’t have those tools in production, however, so we’ll need to package up our code into an executable JAR file.
A JAR file is a Java archive, which is essentially a ZIP file
containing a bunch of compiled Java classes. We could use the javac
command to take our source files and build an executable JAR file.
However, when the JAR is executed, it also needs to be able to find all
the dependencies (for instance, Spring) at runtime in order to use them.
We’ll need to build our JAR file using Gradle so that these dependencies
are packaged up alongside the compiled Java code that we wrote.
Spring Boot adds a plugin to Gradle that allows us to package up our source code alongside any dependencies, creating a fat JAR that contains compiled versions of our code and all of its dependencies. This JAR file can then be deployed to our server, and run anywhere that has the JVM installed. Try building a fat JAR yourself by running
$ gradle assemble
This created a fat JAR which we can run from the command line with the command:
$ java -jar build/libs/coding-events-0.0.1-SNAPSHOT.jar
Our application is now ready to be run on a remote machine. Our next step is to prepare Cloud Foundry to host our application.
In order to deploy an application with Cloud Foundry, you first must
define what your application is and how it should be run. Cloud Foundry
uses a manifest.yml file to manage this configuration. Create a file
at the root of the project named manifest.yml. And add the following
lines.
applications:
- name: coding-events
buildpack: java_buildpack
path: build/libs/coding-events-0.0.1-SNAPSHOT.jar
The name will specify the unique name for our application, in this
case coding-events. The buildpack tells Cloud Foundry what type of
application this is and how to manage it. The path is where to find
our executable project, the fat JAR. If you’re following along with
another project, check build/libs/ to find the name of the JAR you
just built.
Let’s try and deploy our app using:
$ cf push
This will fail. To find out why, let’s try our hand with a little debugging.
$ cf logs coding-events --recent
Now we can view the recent logs from our app (denoted by the
--recent flag). Does anything here look familiar? You’ll see that
our app can’t connect to the database, which makes sense, since we
haven’t set up a remote database for our app.
If you had a project without any service dependencies (like a database), the above steps would be all you need to deploy your application. In our case, we want to also deploy a database. Luckily, Pivotal provides an easy (and free) way to setup a MySQL database in our cloud environment.
First, we need to make some changes to our properties to support our
changes. Update your application.properties so it matches the
following.
# Hibernate ddl auto (create, create-drop, update, none)
# In this case, we'll want the default behavior to do nothing
spring.jpa.hibernate.ddl-auto = none
# Limit the number of active database connections
# Cloud Foundry's Spark databases can only provide up to four connections
spring.datasource.tomcat.max-active = 4
The first property is spring.jpa.hibernate.ddl-auto, which we’ll
change to none. Previously, we let Hibernate manage our
database - creating and updating tables as our model classes change. This is
great for testing, as it allows us to add and change our database schema
on the fly. But in the real world, we have to be careful to maintain our
data in production and be very intentional in the changes that we make
to our database. Allowing tools like Hibernate to automatically modify a
database schema is dangerous. To manage our remote database more
manually, we’ll use another tool in a moment to help manage how our
database is configured.
The second property, spring.datasource.tomcat.max-active, is used to
limit our active connections to our database. Typically, Spring Boot
sets reasonable defaults to the number of active connections, but the
database service we will use (Pivotal’s Spark) only allows four
connections at a time.
Flyway is a tool that uses SQL scripts to create, change, and migrate database schemas and data. These SQL scripts will live alongside our project and will provide a way for us to easily recreate the structure of our database, as well as make additional changes in the future. Flyway tracks scripts that have been executed and detects new scripts and runs them at startup.
First, we add the following dependency to our build.gradle file, in
the dependencies section.
implementation 'org.flywaydb:flyway-core'
Spring Boot will detect this dependency and automatically start using Flyway. We will also need to provide our application with SQL scripts that specify how Flyway should manage our database.
Create a directory in your project called
src/main/resources/db/migration and create a file named in this
directory named V1__initialize.sql. Note that this file name:
Starts with a capital V followed by the migration #. Your second migration would start with V2.
Has two underscores between the version and the rest of the file name.
Has a descriptive tail that makes it easy to tell what this migration includes. For example, you might name your second migration something like V2__add_user_profile.sql
Flyway will load these alphabetically and apply our changes. Since
Flyway keeps track of which migrations it has performed previously, it
is important to not change this file once deployed. Instead, to make a
change to your database, create a new file using the naming conventions
above (e.g. V2__my_new_change.sql).
The easiest way to create our initialization script is to export our
existing coding-events schema. To do this, open MySQL Workbench, select our
database, and choose Server > Data Export. Customize the export by selecting:
The coding-events database from the Schema pane.
All tables in the Schema Objects pane.
Dump Structure Only from the center dropdown.
Export to Self-Contained File from the Export Options pane.
Both checkboxes at the bottom: Create Dump in a Single Transaction and Include Create Schema.
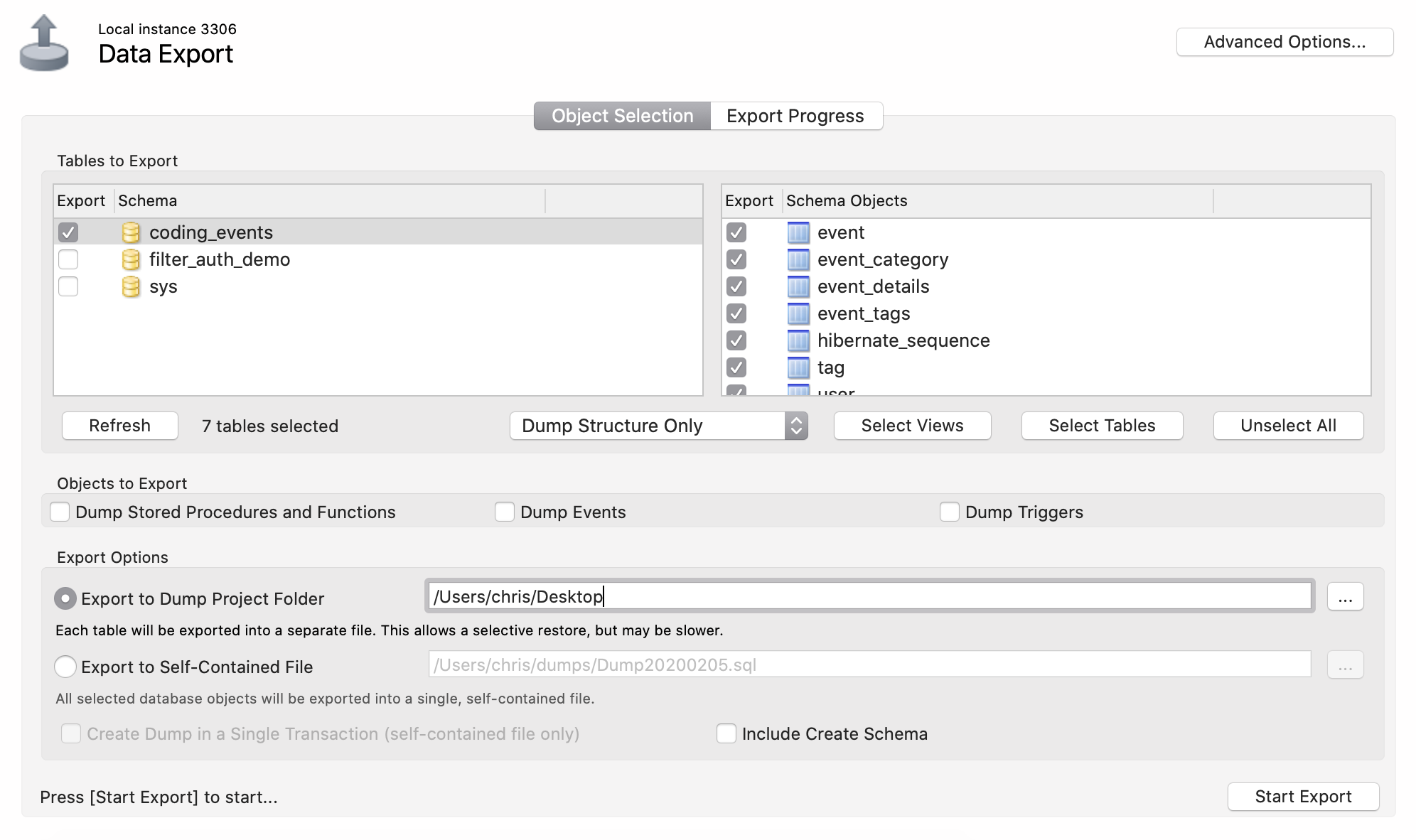
Exporting database schema from MySQL Server¶
Copy the contents of this SQL file into your V1__initialize.sql file. This will
include any test data you have already created, so you may want to clean
up any INSERT statements if you’d like to start with a clean slate.
An example V1__initalize.sql might look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | CREATE DATABASE IF NOT EXISTS `coding_events` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
USE `coding_events`;
-- MySQL dump 10.13 Distrib 8.0.18, for macos10.14 (x86_64)
--
-- Host: localhost Database: coding_events
-- ------------------------------------------------------
-- Server version 8.0.18
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!50503 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `event`
--
DROP TABLE IF EXISTS `event`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `event` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`event_category_id` int(11) NOT NULL,
`event_details_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `FKnk9w760hnelms32e9oqecw6ru` (`event_category_id`),
KEY `FKons5d3ebm4d3233lhlem44ae7` (`event_details_id`),
CONSTRAINT `FKnk9w760hnelms32e9oqecw6ru` FOREIGN KEY (`event_category_id`) REFERENCES `event_category` (`id`),
CONSTRAINT `FKons5d3ebm4d3233lhlem44ae7` FOREIGN KEY (`event_details_id`) REFERENCES `event_details` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Table structure for table `event_category`
--
DROP TABLE IF EXISTS `event_category`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `event_category` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
-- Remaining tables omitted
|
Next, let’s configure a service inside Cloud Foundry for our
database. Cloud Foundry considers anything that isn’t an application to
be a service, and can provide pre-configured services to help speed up
deployment. In this case, we want to create a MySQL database service for
our application. Pivotal has a database called cleardb, a flavor of
MySQL designed for cloud hosting. The spark instance size is free and
will be fine for almost all student projects. Creating a service in
Cloud Foundry will also manage passwords and inject them into the
application. This means that we do not need to check in our database
credentials into version control (because we shouldn’t!).
Create a new service:
$ cf create-service cleardb spark coding-events-db
Check running services:
$ cf services
You should see your newly created service displayed but no application tied to it.
Now you need to attach our application to your service. Cloud Foundry calls this service binding and provides a network connection between the application and the service. This also removes the need for us to manually define and configure our database URLs.
$ cf bind-service coding-events coding-events-db
We can confirm this has been configured by running cf services
again, and we should see our app name has been added.
Once this has been established, it does not need to be re-bound when we redeploy.
Above, we manually configured our service binding for our application.
Alternatively, the manifest.yml can bind services as well. Update
your manifest.yml to the following:
applications:
- name: coding-events
buildpack: java_buildpack
path: build/libs/coding-events-0.0.1-SNAPSHOT.jar
services:
- coding-events-db
Now that there is a database service, and matching service binding, deploy your app again:
$ cf push
We should see a message that our application has started. Open up the
Pivotal Control panel, select your
space, and find your application. Click the Route Tab to see the
public URL of your application. In my case, it was
https://coding-events.cfapps.io. But yours may be something else, since
these must be unique and are generated for you. Be sure to append
/events onto the end of the url (i.e.
https://coding-events.cfapps.io/events, and try out your newly deployed
app. Cloud Foundry has handled all of the network routing for us, so we
don’t have to configure this ourselves.
All good things must come to an end. Or, at the very least, will be billed hourly. When you’re not showing off your new application, it’s economical to stop the service.
To stop an application:
$ cf stop coding-events
And when you’re ready to use it again
$ cf start coding-events
Since the spark instance of our database is free, we can leave it running. This way we can always have some test data in our application to demo. However, if you like, you can remove the database service as well.
To do so, first remove the service binding, which ties the database to the application:
$ cf unbind-service coding-events coding-events-db
Then, remove the database service:
$ cf delete-service coding-events-db
And then you can delete your application entirely:
$ cf delete coding-events
Once you start making changes to your own applications, you are going to want to be able to easily deploy your application. It may be helpful to build some helper scripts, so that you don’t have to remember all the right commands. Here is an example of a deployment script you can use:
deploy.sh:
#!/usr/bin/env bash
# Clean up any old artifacts, and rebuild the jar
gradle clean assemble
# Create the database (will give a warning if already exists)
cf create-service cleardb spark coding-events-db
# Deploy to cf
cf push
Mac and Linux users should be able to deploy the application via
sh ./deploy.sh. Windows users, if you have Git Bash installed, open
a new Bash prompt and do the same.
Alternatively, you can make the script executable using
chmod +x deploy.sh. Then it will be directly executable via
./deploy.sh.
You can script the destruction of your application as well. These commands will completely delete your application, database, and any associated information, so be careful with them!
destroy.sh:
#!/usr/bin/env bash
# Stops the running app
cf stop coding-events
# Removes the binding between services
cf unbind-service coding-events coding-events-db
# Removes the db service
cf delete-service coding-events-db -f
# Deletes the app entirely
cf delete coding-events -f
How can I keep a set of properties for local development to connect to my database? Using spring profiles, and two sets of property files, you can create properties for both local and deployment. Read more about profiles in Spring.
How can I work with logs for my deployed Java application? Logging gives valuable info about your running application, including the potential sources of errors. Read more about logging in Java.