24.2. Database Structure¶
Databases store information in tables. These are arranged in columns and rows. Each column represents a specific piece of data. Every row represents a single entry in the table, which includes one value from each column.
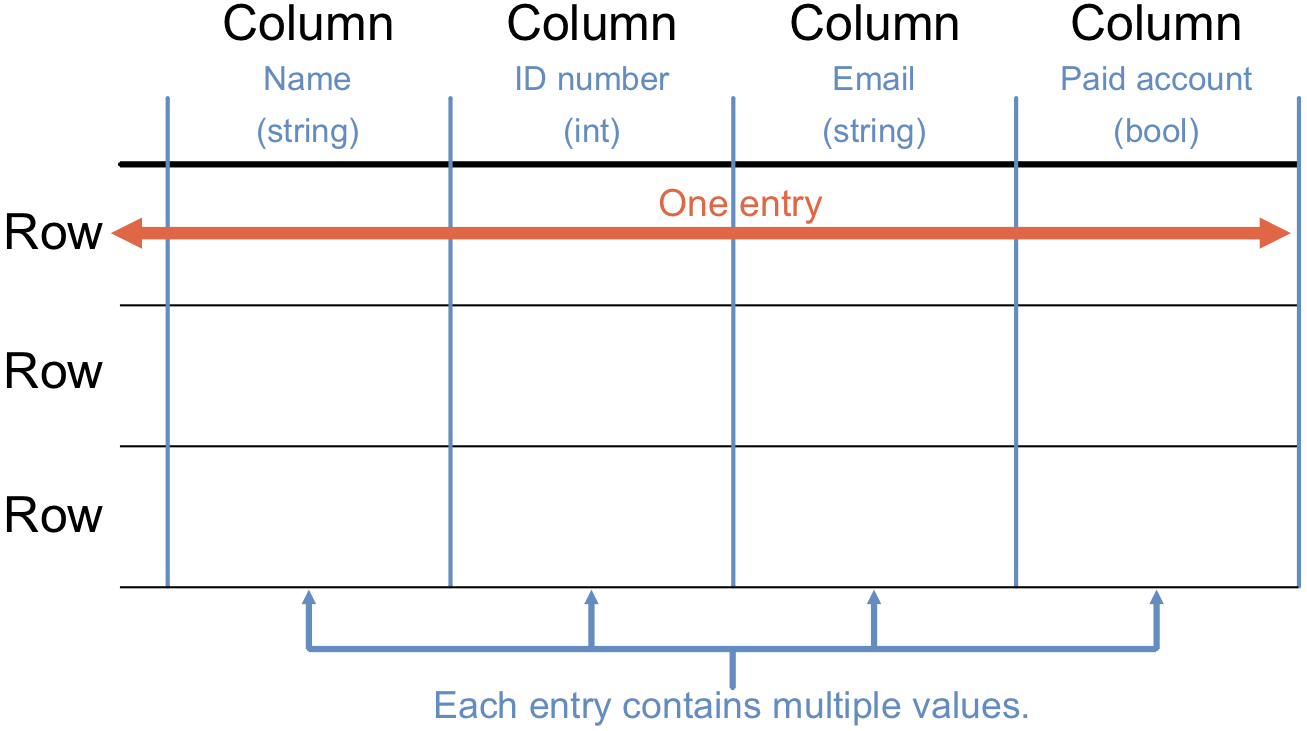
Each row is one entry. Every entry consists of multiple data values, arranged in columns.¶
Points to note:
Each column holds a particular data type, like integers, strings, lists, etc. All values in a column must be the same data type.
Each column also has a label that tells us what the data represents. For example, one column might have a
Last Namelabel, while another could be calledEmail.Each row includes a primary key, which helps us manage the data. No two rows share the same primary key.
When we add or remove an entry, we create or delete an entire row.
When we change an entry, we modify the value in one or more columns of a single row.
The number of entries in a table is equal to the number of rows. The number of data values for each entry matches the number of columns.
24.2.1. Relationships Between Tables¶
Imagine you visit the website for your local library, which uses a program for the online catalog. To find a book, you can search for its title, the author, a keyword, etc. Given the huge number of books available, the library database stores a massive amount of information. How is this organized?
Imagine a single table where each row corresponds to one book. The columns would include things like the title, a short summary, the author’s name, the author’s biography, the publication date, the number of pages, whether the book is checked out, etc.
Stuffing all of the data into one place is inefficient. Think about how often each author’s biography would be repeated! Just like we DRY our code, any piece of information in a database should only be recorded once.
A better approach is to create multiple tables in the same database. Each one
holds information that falls into one category or idea. For the library, the
tables could include Authors, History, Science Fiction, eBooks,
etc. Using multiple tables avoids duplicate entries. We store an author’s name
and bio ONE time, regardless of how many books they have written.
Once we have multiple tables saved in a database, the next step is to create
links between them. We call these links relationships.
Relational databases store data in a series of connected tables. For
example, imagine we look up a science fiction title and want information about
the author. The Science Fiction table does NOT contain this data. However,
it does have a relationship to the Authors table. The catalog program can
follow the link between the two tables and retrieve the desired data. Since
multiple book titles can link to the same author, we only need to store the
writer’s data one time.
Not only can we identify the author from a title search, we can also use the
writer’s name to return a list of all of their book titles. By connecting
tables together in this way, relational databases provide efficiency and
flexibility. If we update an author’s biography, we only need to do that once
in the Authors table. Anything that links to Authors can access the new
information.
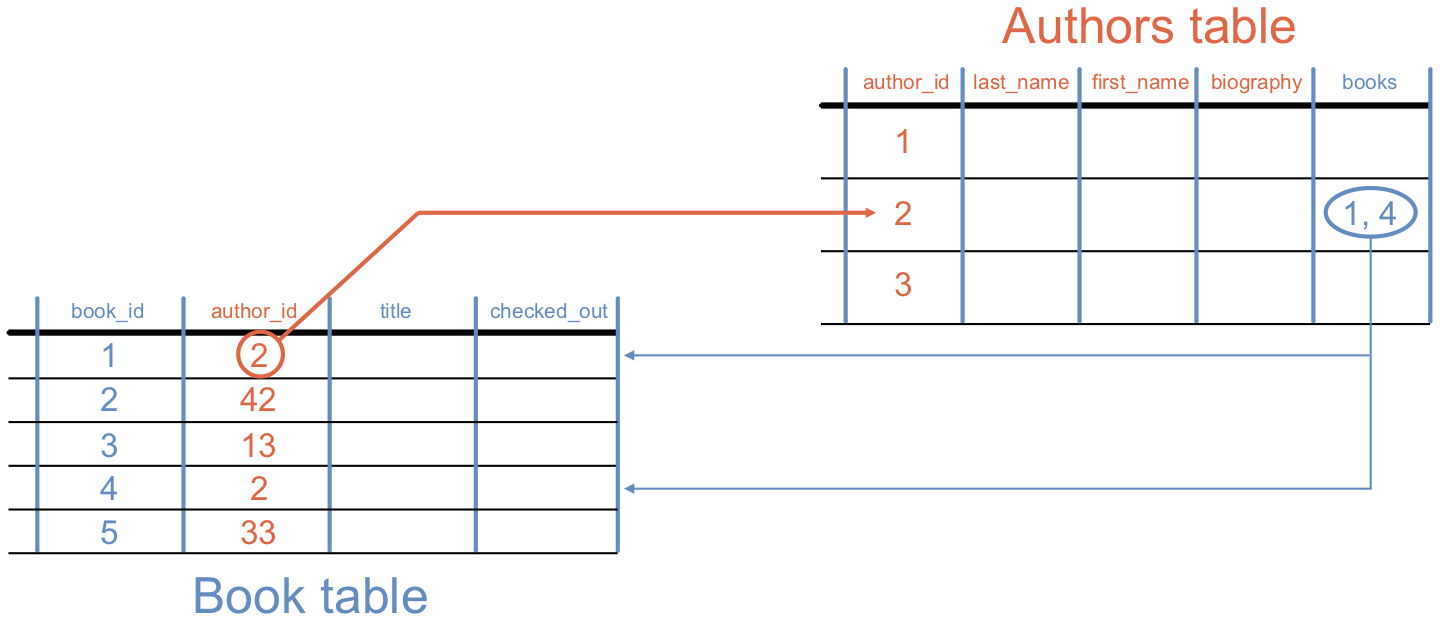
A column from the Book table forms a relationship with rows in the
Authors table, and vice versa.¶