Branches
Branching in Git
So far, this book has talked about Git’s ability to store different versions of a code base. What if two programmers want to work on different features of the code base at the same time? They may want to start with the same version and then one programmer wants to change the HTML and the other the CSS. It would not be effective for the two programmers to commit their changes to the repository at the same time. Instead, Git has branches. A branch is a separate version of the same code base. Like a branch on a tree, a branch in Git shares the same trunk as other branches, but is an individual. With branches, the two programmers can work on separate versions of the same website without interfering with each other. Besides collaboration, programmers also use feature branches to store and test new ideas for their software.
In the previous section, when checking the status, the top line was
On branch main.
The main branch is the default branch of the repository.
Many programmers keep the live version of their code in the main branch.
For that reason, major work should be done in a new branch, so it doesn’t impact the live software.
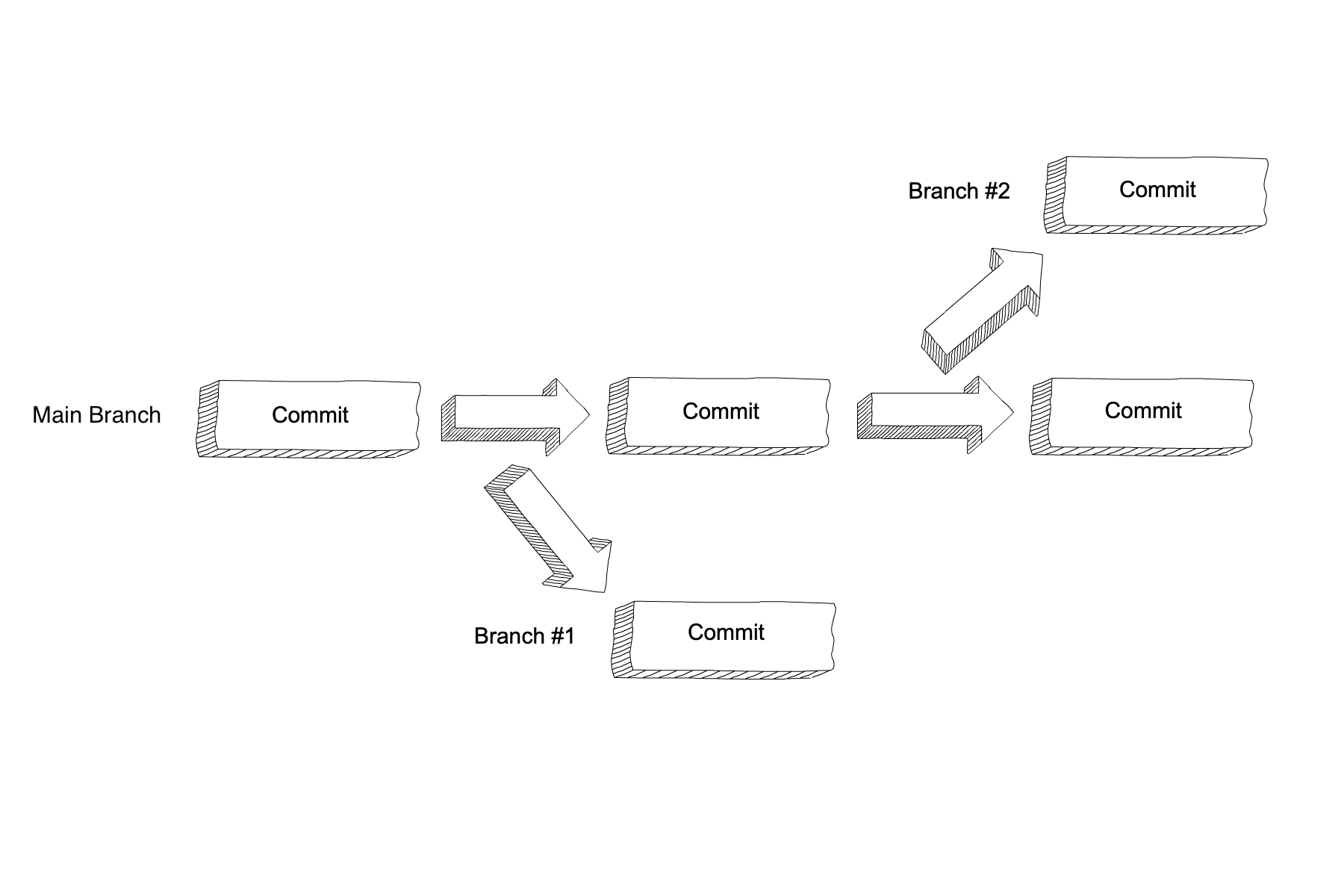
Creating a New Branch
Assume a programmer is on main and they want to start building a new
feature in a new branch. Their first step is to create a new branch for their
work.
To create a branch, the command is git checkout -b <branch name>.
By using this command, not only is a new branch created, but also the programmer switches to their new branch.
Switching to an Existing Branch
If the branch already exists, the programmer may want to switch to that branch.
To do so, the command is git checkout <branch name>.
Check Your Understanding
What is a reason for creating a branch in Git?