14.1. Exploratory Data Analysis¶
Read the following articles, follow along where instructed.
Note
You do not need to install pandas, it comes with Anaconda.
Tip
For Medium articles: if you run out of free articles, open the page in an incognito window.
14.1.1. Exploring Data with Python¶
Code along with this article.
Stop at Step #8 “Detecting Outliers”.
14.1.2. Get to Know Your Data¶
14.1.3. Python pandas¶
Code along with this article.
Python Pandas Tutorial: A Complete Introduction for Beginners
Stop at “Handling Duplicates”.
14.1.4. Statistics in pandas¶
14.1.5. What is a DataFrame?¶
A pandas DataFrame is similar to a Python dictionary. The column names are like keys and the values are the data for that column.
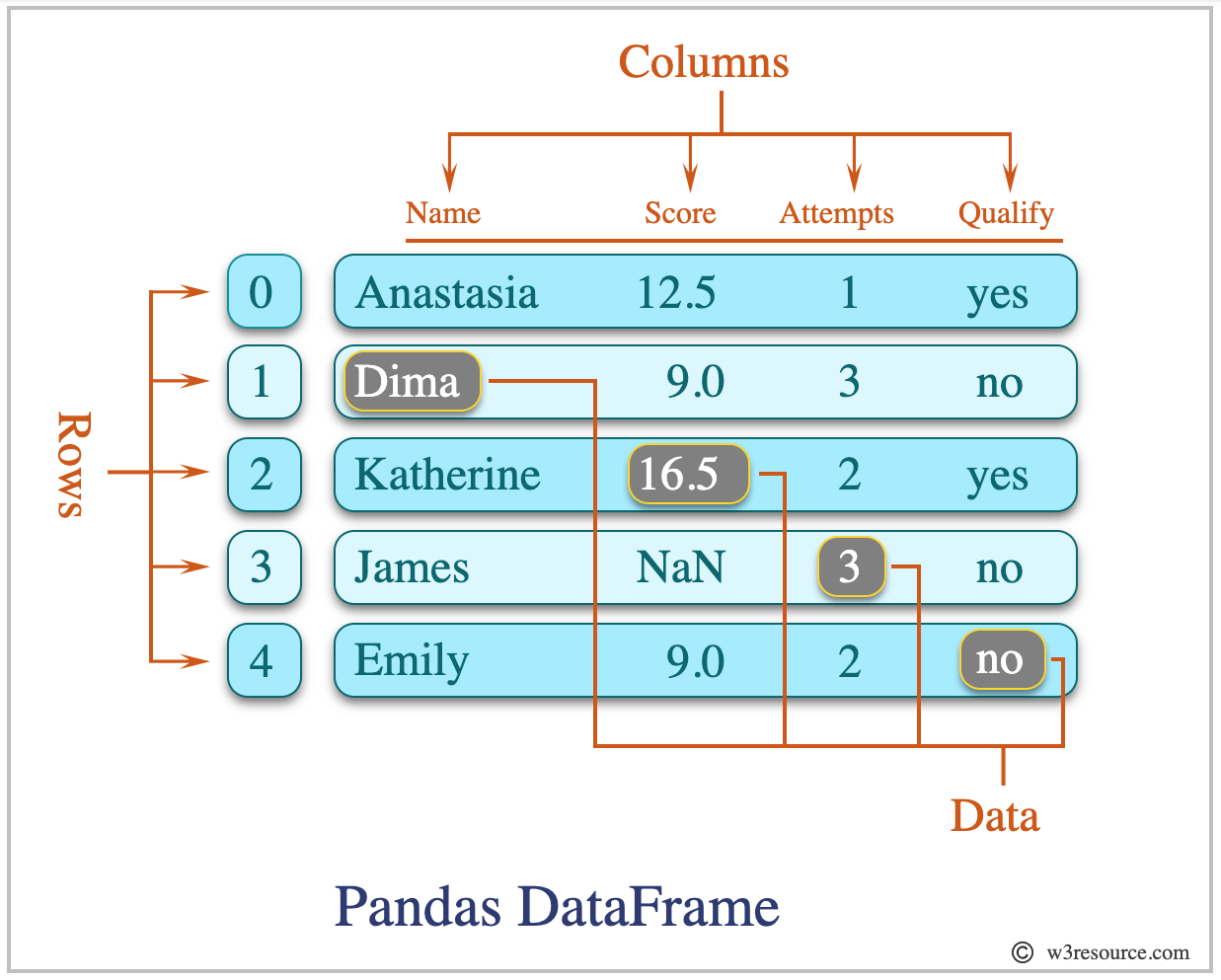
For more information about pandas DataFrames and the diagram above, visit w3resource.¶
pandas Series. Here is how pandas Series are used to build a dataframe.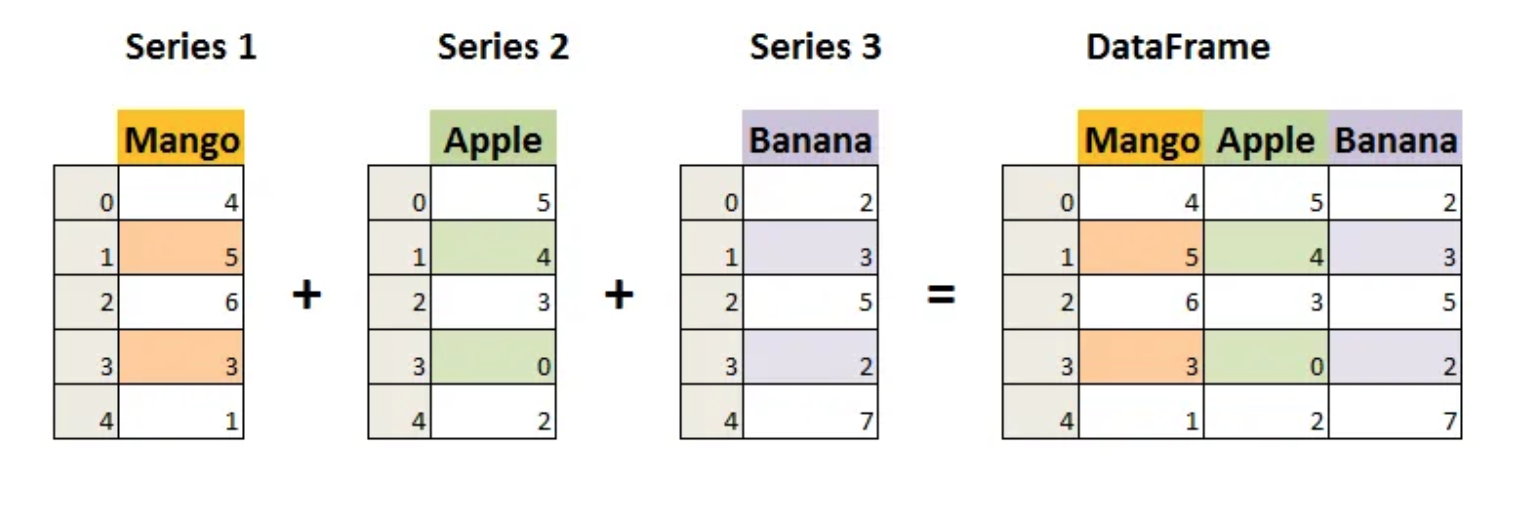
For more information about pandas Series and diagram above, visit w3resource.¶
14.1.6. Check Your Understanding¶
Question
What is the pandas function used to return the number of rows and columns in a DataFrame?
Question
Column names cannot be changed in a DataFrame?
True
False
Question
What can knowing the data types present in a data set tell us about the data being presented?
Question
What is the pandas method for reading a CSV file type?
Question
Visualized below is the “purchases” DataFrame . What is the pandas syntax to select for Robert’s data?
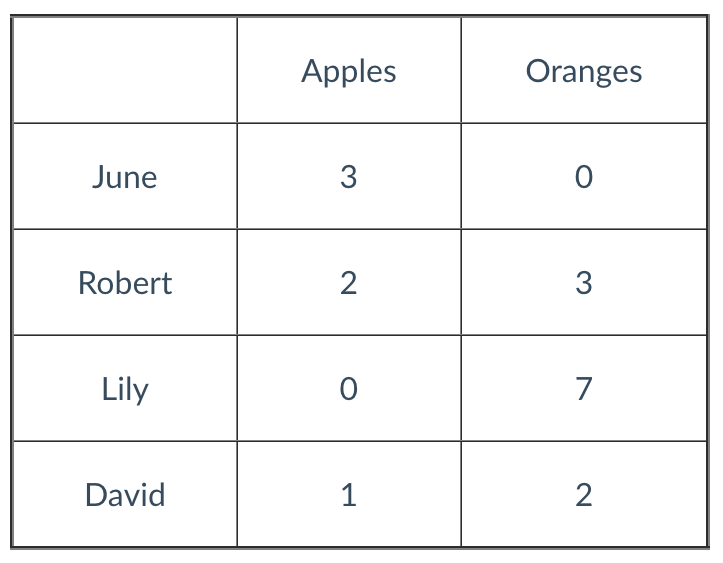
Question
How do we view only the first 13 rows of a DataFrame?
Question
A DataFrame column is a Series?
True
False
Question
Which pandas function will print the number of records, three quartiles, mean, standard deviation, minimum and maximum values of a DataFrame?
.describe().index().statistics().head()